
How do we use machine learning to build a loan calculator that benefits lenders and recipients?
Let’s start with the basics:
Buying a home is one of the most important financial decisions an individual has to take. Since it is considered a long-term financial investment, mortgage lenders are discerning when deciding who receives a loan or not. The lender profits from interest if the borrower pays back the loan in full. However, the lender risks losing money if the borrower defaults on the payments. There is a strong incentive to predict borrower behavior to prevent the latter from occurring.
Mortgage underwriting is assessing loan eligibility based on an individual’s finances. To be specific, this includes verifying employment, assessing income and assets, and examining his or her credit history. Since conducting a manual assessment takes a long time (up to 60 days), it makes a lot of sense to automate this process using computer models.
Machine learning (ML) shows considerable promise in this area, since it allows underwriting staff to handle a larger volume of requests and focus on more unique cases. These efficiency improvements also allows potential homeowners to more quickly close on their future home. In a recent loan-lending study, an ML approach could reduce defaults by 75% and increase approval rates by 173%.
The appeal of this value proposition has garnered attention from mortgage executives. According to one survey, roughly two-thirds of lenders are familiar with the technology, with 27% incorporating them to their businesses. Nearly three-fifths (58%) of those surveyed expect to see an ML-driven approach over the next two years.
Despite the potential, lenders have a responsibility to comply with regulations and ensure that the technology is used effectively. This includes ensuring transparency in a model’s decision-making process — like giving specific reasons why an individual has his or her loan denied or approved. Fintech startups like Lenddo and Personetic are aware of this greater trend toward automation for lending. They have taken steps in streamlining the loan process and improving the customer experience, which will be discussed later in detail.
With all this anticipation, you may wonder how exactly does ML automate the approval process. I have broken up the article into two parts to address this topic:
- How Machine Learning is Automating Loan Approval
- Challenges and Future Steps
How Machine Learning is Automating Loan Approval
Data Collection
As previously mentioned, a loan approval tool must collect the required financial information to reach a loan decision. Plaid developed an API that allows one to extract this data from different banking institutions. After setting the credentials up, this API collects information on individual income, length of employment, account balance, assets, and past transactions. It can also supply personal data such as social security number (SSN) and verification of residency (address) upon request.
For the verification of credit history, three major vendors (Experian, Transunion, Equifax) offer individual APIs to collect a person’s credit report. Certain services such as Universal Credit aggregate the reports from the three aforementioned vendors for easier verification.
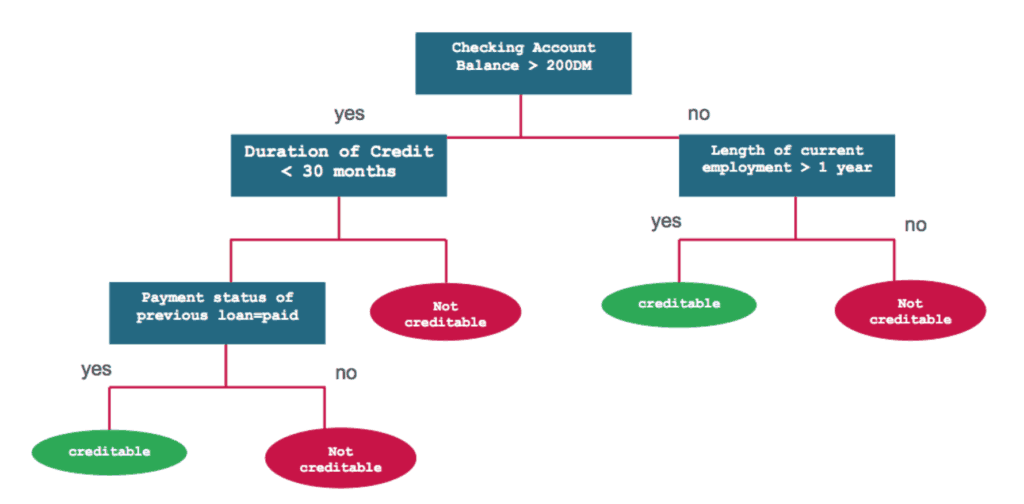
Decision Making Process
Once the proper information is gathered, the computer must make a decision on whether to approve the loan. In machine learning terminology, this is a binary classification problem — the computer is trained to label (classify) future loans based on the aforementioned features (i.e. financial information). One technique to enable this is to construct decision trees from the given information.
Decision trees work by answering a question at a given node, and navigating through the next branch depending on the individual response. As one can see, decision trees are very easy to explain and interpret, which meets the requirements for transparent loan-lending. However, it is easy to make poor predictions (overfitting) for very large trees, since the model can be trained to “learn” the noise from the data. It would be the equivalent of asking a very specific question to a problem that has little to no actual relevance.
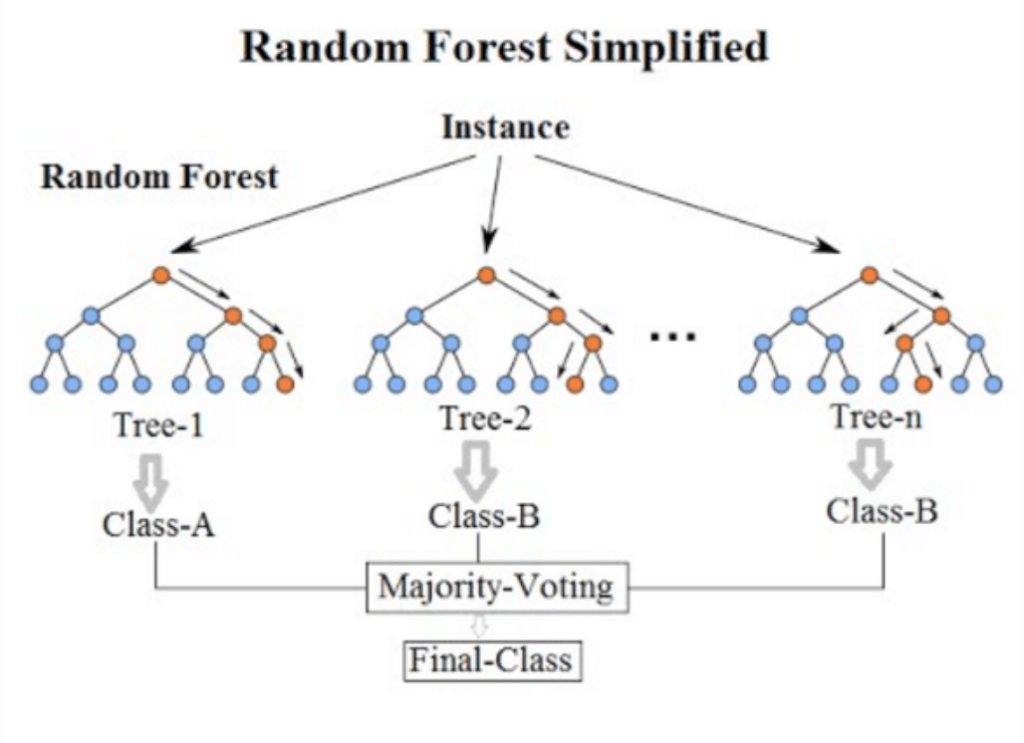
To address this issue, we can create a set of models and aggregate their results to get a more robust prediction. Random forest uses this ensemble approach by building out multiple decision trees based on different, random subsets of data. Essentially, each tree makes an individual decision, and the label is decided based on a majority vote. Since decision trees are relatively independent of one another, combining their results cancels the individual errors found in each.
To give a real-life analogy, it would be like getting multiple perspectives on a complex topic, with each individual specializing in their domain. Developing a robust solution requires one to see through several lenses, each highlighting a particular aspect of a problem.
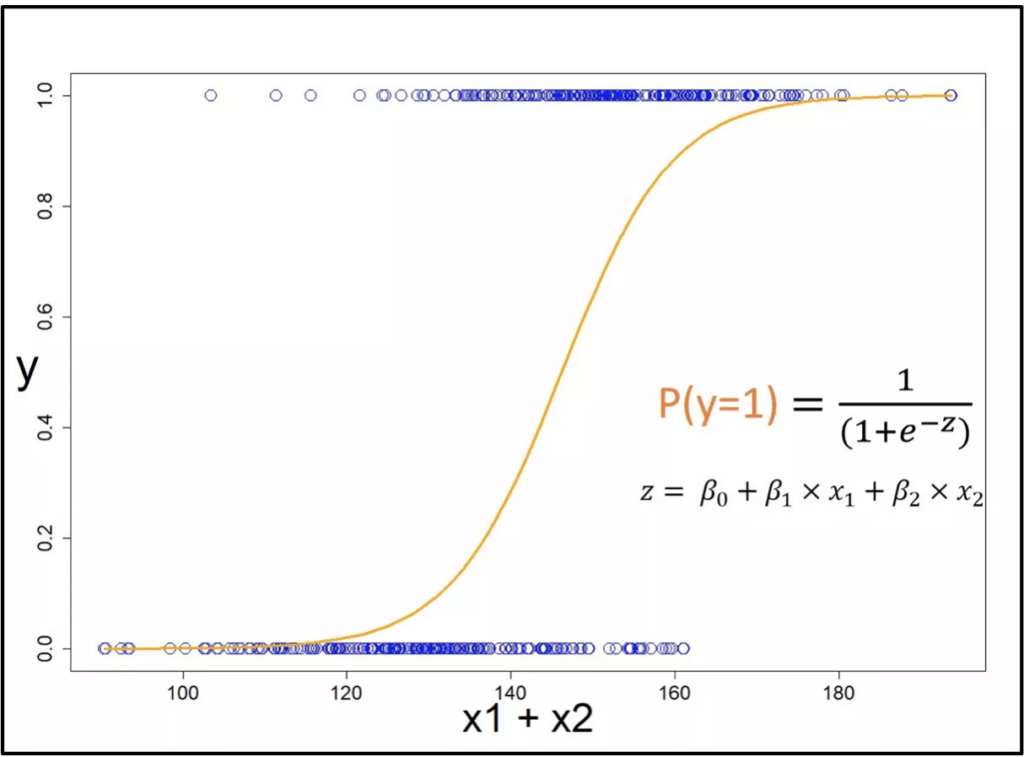
In addition to tree-based models, automated mortgage underwriting can also be done through logistic regression.
To understand this approach, it would be useful to explain linear regression first, its simpler counterpart. In linear regression, we predict an output value (y) based on certain individual features (xn). Certain features contribute more to the final result — this is indicated by higher weight values (bn).

As a related example, house sellers use this model to gauge the house price (output value) based on certain features (i.e. number of bedrooms and bathrooms, number of square feet of property etc.). You may wonder at this point — how do I reframe this output value into a yes/no answer (instead of a number), and how does this apply to loan lending specifically?
Logistic regression takes this one step further — it calculates a probability value (0 to 1) based on the aforementioned output value (y). This is the likelihood that a particular observation belongs to a certain class or not. The label is then decided based on some predetermined threshold (often set at 0.5 or 50%). In the context of lending, let’s say a person is in severe debt and has a bad credit history. Based on these factors, the model may calculate that this individual has a 2% of repaying back the loan. Since it is below that threshold, the model can reject giving the loan to that person.
Logistic regressions are beneficial in that the loaner may want to control loss at an acceptable level. For instance, he or she may set a higher threshold (say 0.85) in order to minimize loss. This change comes with a trade off — more potential borrowers will be flagged and their financial information will be manually audited by the underwriting staff.
Building the Application
Now that the concepts are laid out, you may wonder — how do you actually develop a loan approval application? As mentioned in previous articles, it is recommended that you use off-the-shelf components (i.e. third-party services or libraries) if it makes sense for your application. In other words, avoid reinventing the wheel whenever possible.
Check out our article How to Make a Machine Learning App.
With that said, the machine learning techniques mentioned previously can be found using Python’s scikit-learn. This library contains off-the-shelf algorithms (i.e. random forest, logistic regression) for binary classification problems. It is a more high-level library compared to TensorFlow, as the latter is more focused toward the nitty-gritty computation side (i.e. matrix computations, vectorization, GPU optimization). For this application, the main advantage of using a high-level library is that it allows you to focus your efforts toward work that produces long-term value (i.e. feature selection, rapid model iteration). Moreover, sci-kit learn is also used in production systems at financial firms such as J.P. Morgan.
Given the benefits of this framework, let’s discuss the general steps to build a robust model. After the APIs collect different financial information (i.e. credit history, income), this data needs to be cleaned up (pre-processed) prior to model development. Scikit-learn offers multiple options to address different scenarios such as missing data (i.e. lack of residency verification) and outlier cases (i.e. unusual debt-to-income ratio).
To give a scenario, let’s say the user has missing income data based on the pulled information — you decide to err on the side of caution and assume zero annual income (unless proven otherwise) to minimize any potential losses. The library also offers tools for data standardization, since machine learning models work best when different features are on the same scale.
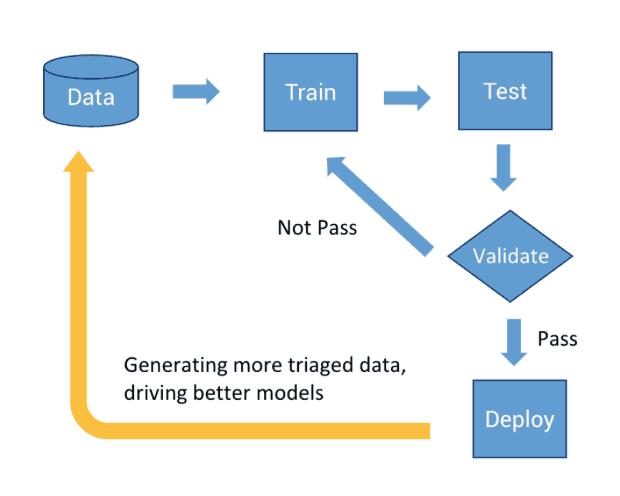
Once the preprocessing steps are complete, we then start coding our model. Functions such as random forest or logistic regression are fairly intuitive to use — with only a line of code, you plug your data in, set your parameters, and the function outputs your model. This step involves splitting the data into two parts: training and testing.
The general idea is we train the model using our training data. We then evaluate our model on new (test) data, and compare the predictions to the actual results (accuracy). It is important to emphasize that the ML development process is iterative — your models will improve when you evaluate your results (good or bad) with a critical eye. Being discerning will also help in refining your understanding of the problem.
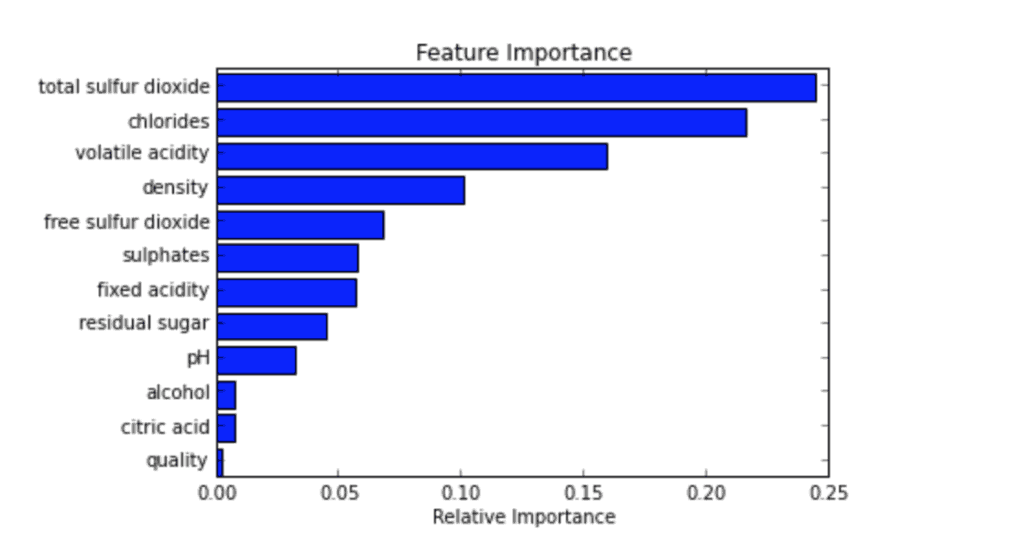
During model evaluation, you may assess what factors contribute most in the decision-making process. Luckily, scikit-learn offers a good range of programming functions to choose from depending on the chosen ML algorithm. One algorithm worth highlighting for this application is recursive feature elimination (RFE). The general idea of this approach is that you repeatedly build models and leave out the “worst” performing features during each round. The remaining features are trained in subsequent models — and the process stops once all features are exhausted. Each feature is then ranked based on elimination order.
By removing irrelevant features, you reduce your model training time — which is conducive to model iteration and development. Moreover, it also increases model accuracy, since you are reducing the possibility of overfitting on “bad” features. To give one example, borrower age may be an irrelevant factor if other features provide evidence that he or she can make timely payments.
Understanding feature importance also has real-life implications beyond just refining models. To illustrate, let’s say the borrower got rejected after applying for a loan. He or she can prioritize what steps to take in order to get their application approved for next time. Simpler models are also easier to interpret and explain, which is an essential requirement in the loan-lending industry.
After model development, you may consider deploying it in a mobile or web application. Flask is a Python web framework that can make API calls to the model on the front-end. The primary benefit of using this framework is modularization — the code that is used for machine learning is separate from the one involved in other parts of the application. This clear division of labor allows developers to work on their parts without any unnecessary delays.
Challenges and Future Steps
While the technology behind automated loan underwriting shows promise, it is important to address potential risks. In the financial services industry, there is a term called “model risk” — it essentially refers to the possibility of errors resulting from inaccurate input data, misuse of models, or from faulty calculations. This issue is not a theoretical one based on current events. In one related incident, Wells Fargo had a computer glitch where it incorrectly denied 870 loan modification requests, resulting in 60% of those homes foreclosed. Developing black-box models contributes to this risk, since they cannot be properly audited by an independent reviewer.
To mitigate the risks, developers should follow best practices by documenting their processes and increasing transparency in their automated models. There should also be human input involved at different steps in the process — this may mean doing regular audits of model decisions, or using the tool more for assistive intelligence (individuals make the final call).
Despite the challenges ahead, Fenddo and Persoentic are establishing new frontiers on how loans are being borrowed. Fenddo uses alternative data sources to establish the creditworthiness of an individual — this includes looking at a person’s browsing history, geolocation data, and social media use.
All this information turns into a credit score, which is then subsequently used by banks and lenders to determine whether to give a loan. Persoentic is another firm that provides banks AI techniques to improve customer experience. One example of this is making automated payment suggestions based on the user’s financial habits. This resulted in greater engagement from users and a significant reduction in operating costs (fewer people need live assistance).
Are you looking to contribute to this greater trend and start building your own loan approval tool today?
Here at Topflight Apps, we can help flesh out your machine learning ideas and develop your applications that produce lasting value. We are a team of fintech app developers and founders who are not afraid to tackle new challenges and embrace new perspectives.
If you are convinced, please request a proposal on our website. We look forward to hearing your ideas!
Related Articles: