
The ability to track body movements used to belong to sci-fi and required Star Wars-grade hardware. Today, you can try out pose estimation in a browser, even on a smartphone. As this AI technology becomes more accessible, businesses find new exciting ways to apply it in various industries.
So whether you’re a physical therapy or fitness startup looking to take advantage of this breakthrough technology, expect to learn all the nitty-gritty from this primer. We’ll discuss how pose estimation works and what tools are available to enable this body tracking tech in your mobile or web product.
Table of contents:
- What is Pose Estimation?
- Areas of Application for Pose Recognition
- How Does Pose Estimation Work?
- Tools for Pose Estimation
- How Pose Estimation Pushes Fitness Further
- Time to Use Pose Estimation is Your App
What is Pose Estimation?
If you’re wondering what we mean by pose estimation or human pose detection, I’m glad to report it’s no longer rocket science; at least on the surface. We are talking about an artificial intelligence technology that relies on machine learning algorithms to analyze images.

The idea is that algorithms running on neural networks perform human pose recognition and track body movements in real-time, using a camera and a little bit of magic.
That’s obviously a very high-level description of the computer vision techniques used to track a person’s pose at any given time. We’ll share more insights in a minute.
Areas of Application for Pose Recognition
Before we dive into details of computer vision operations, let’s first review the main areas of application for pose estimation technologies.
Fitness
Fitness is the first thing that immediately comes to mind when we think about automatic pose detection. Many startups are exploring AI capabilities for pose recognition in this area.
This technology allows them to create AI-powered personal trainers that check how customers perform exercises and whether they need instructions to correct their body position. Such fitness apps democratize services of personal coaching:
- lower cost of having a one-on-one professional trainer
- minimal injury risk
Physical therapy
Another trend where camera pose estimation is getting traction is physical therapy app development that detect body postures and provide feedback to users about specific physical exercises. The gains, again, are:
- lower cost of care as no to minimal physical therapist involvement is required
- better health outcomes for users
- convenience of at-home exercises

Related Article: Computer Vision in Healthcare
Entertainment
Pose detection software can also help replace expensive motion capture systems used during film and video-game production. And in video games, recognition of movements can help create more immersive experiences. For example, Kinect can track the player’s movements using IR sensors and relay them to her virtual avatar’s actions. The upsides include:
- lower cost of movie production
- more engaging user experience
Robotics
Controlling robots is yet another application for this computer vision technology. In this case, robots’ rigid logic and movements are replaced with pose detection and estimation algorithms that allow for a more flexible response.
- minimal recalibration
- quick adaptation to a variety of environments
How Does Pose Estimation Work?
The basic principle behind pose estimation is the processing of RGB (aka normal, regular) or infrared (IR) images with machine learning algorithms running on convolutional neural networks.

RGB images-based pose detection is easier to implement than IR because many mobile devices and laptops have built-in cameras. As for IR images, these can be captured by Kinect and RealSense infrared cameras.
Skeleton recognition
The neural network tracks the human body’s main joints (e.g., knees, elbows, feet) and then, based on their relative position, reconstructs a human skeleton and its movements. Different positions of key-points correspond to various postures.
Bottom-up and top-down approaches
To keep things simple, let’s just say that with the top-down approach, pose recognition algorithms first identify a human. After that, each human object is placed in a virtual box and their posture is analyzed by tracking key points inside the box.

As for the bottom-up approach, joints are grouped into hierarchies and, eventually, skeletons, eventually arriving at body position recognition.
Body Model
Convolutional neural networks need to have a clearly defined body model before they can begin to id poses. Simple kinematic body models include 13 to 30 points, while more comprehensive body models — mesh models — may consist of hundreds and thousands of points.
Pre- and post-processing
Proper pose estimation also presupposes some pre- and post-processing of imagery. Pre-processing may include removing the background in the image and adding body contours (placing each recognized person in a box). Post-processing involves geometry analysis — is this a natural/possible pose for a human?
Based on the analysis, a fitness app featuring such an AI assistant can suggest to users what they can improve about their exercises.
Multi-person vs. singular-person pose estimation
As you’d imagine, multi-person pose detection is more challenging than single-person because a neural network needs to successfully identify each person and only then start decomposition of their postures.
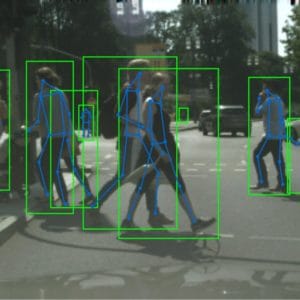
Moreover, people may block each other’s view and interact with each other in a way that makes body recognition extremely difficult.
3D vs. 2D pose detection
Pose detection algorithms may work with either 2D or 3D pose estimation. With 2D, they estimate poses in an image, and with 3D human pose estimation, predict poses in an actual 3D spatial arrangement, similar to how Kinect works.
3D pose recognition is more challenging since we have to factor in the background scene and lighting conditions. There are also fewer available 3D datasets.
Images vs. video
We’ve already established that pose detection happens in images. And the only difference with pose estimation in the video is that software needs to decompile a video into a series of images. These images are then processed for pose recognition.
Of course, pose estimation in videos has its advantages because neural networks have access to gradual changes of postures and spot the frames where certain body parts are clearly seen (as opposed to the frames with occluded body parts).
Tools for Pose Estimation
First of all, we should mention that pose estimation for the 2D and 3D approaches requires different toolsets. Let’s review what’s available for 2D vs. 3D pose estimation.
Two-dimensional pose estimation
Companies such as Google have already developed specialized neural network architectures designed explicitly for 2D pose estimation. With their machine learning model PoseNet for real-time human pose estimation, we don’t even need to train a model.

PoseNet
Google provides two versions of PoseNet: one for single-pose detection and the other for multiple-pose estimation.
The way PoseNet model works is it takes an image from a camera as an input and resizes it so the model can run it. The next step for the model is to output information on 16 body parts and compile them into a skeleton.
On top of that, the model provides the confidence score of poses, which can be thresholded to filter out poses where the system is not sure how to classify them.
PoseNet for Mobile and Web
PoseNet is available on TensorFlow Lite (another Google’s open-source software for machine learning) and can be used to build iOS and Android applications with pose estimation.
As for enabling web experiences with PoseNet, you can run it on TensorFlow JS. Google provides real-time pose estimation for testing in a browser.
Of course, the beauty of using PoseNet with TensorFlow JS is that all data remains locally on your computer, and you don’t even need any specialized hardware or sophisticated system setup. Tensorflow pose estimation using Tensorflow JS is open-source, and developers can tinker with the code freely to fit their application.

Three-dimensional pose estimation
For 3D pose estimation, we can use Kinect or RealSense cameras. They have their pros and cons; let’s quickly review both.
Kinect
Kinect is a relatively cost-effective camera from Microsoft for movement analysis, with a built-in depth sensor that captures depth data based on a video feed of infrared images.
For development purposes, you will need Azure Kinect Developer Kit, which includes hardware (the camera) and two SDKs: for working with the depth sensor and body tracking algorithms.
After installing the required libraries and prerequisites, you just pull the code from Github and can start building your pose estimation app. The demos from this Github repository display information about joints by tracking the body orientation and depth and offer air writing, among other things.
Some of Kinect’s benefits include:
- ability to estimate pose depth at broad ranges (up to 5 meters)
- supports output up to 30 frames per second
- body tracking algorithm is pre-trained on a large dataset
![]()
RealSense
Alternatively, you can also use the RealSense camera from Intel. RealSense provides many of the same benefits as Kinect in terms of capturing depth and color information at high resolution, but a higher rate — 90 frames per second. As a result, output models move smoother.
From the development perspective, RealSense provides more than enough. Their SDK is available on Github and includes a viewer, a depth quality tool, debug tools, and quite a few wrappers to integrate with third-party libraries.
Besides that, they offer a standalone skeleton tracking SDK, with one disadvantage — it’s not free ($75/license). Otherwise, it’s an excellent solution for working with pose estimation:
- сross-platform (supports multiple language interfaces)
- supports multiple people tracking
- no specialized hardware required, such as GPU
How Pose Estimation Pushes Fitness Further
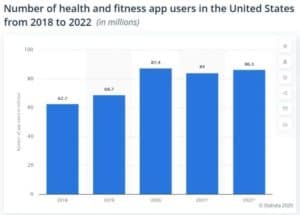
The digital fitness industry has seen incredible growth since COVID-19 hit us. Health and fitness downloads grew by 46% worldwide in 2020, and the industry is expected to grow to $16 billion by 2025.
Application of artificial intelligence to fitness and personal health industries helps to further two thriving trends:
- at-home fitness
Fitness apps allow for the convenience of one-on-one training without high costs.
- increase in computer vision capabilities and motion tracking devices
As a result, health expertise and fitness data are being democratized.
Read Also Our Guide How to Build a Fitness Tracker App
Notable startups
Mirror is a digital mirror that turns into a monitor for training sessions. Its ML-based software analyzes your movements and provides real-time feedback based on user preferences and goals.
Motion Coach by Kaia Health is a mobile app for iOS that uses computer vision and iPhone’s selfie camera to provide audio prompts and visual feedback to help you exercise more efficiently. In addition, the app counts repetitions.
Vay is a Zurich-based startup that features an app analyzing exercises similar to Kaia Health. Vay’s creators boast a quickly expandable base of exercises and independence from the camera position.

TwentyBN, an AI startup that has built Millie Fit, a fitness kiosk with AI coach Millie. It combines video understanding and NLP, leads, and corrects your workout in real-time. Highlights:
- AI system relies on crowd-sourced data from their users
- tracks a variety of exercise movements: 30 exercises overall
More than 42 of the world’s top 100 universities and 2 of the top 50 companies on Forbes Global 2000 already use TwentyBN technology for research and commercial purposes.
Time to Use Pose Estimation is Your App
We’ve put together a quick prototype to show how AI pose recognition works. It’s a free stock video of a running man that we processed with our ML model to analyze the runner’s body joints and movements.
Do you have questions about how you can enable pose detection in your fitness, physical therapy, or other apps? Get in touch, and we’ll show you how this technology can work for you and your users.
Related Articles:
- How to create a machine learning application
- Role of AI in Healthcare Applications
- How to Build a Fitness App
- Use Cases of Machine Learning in Healthcare
- How to Create a Physiotherapy App
This blog was originally published on 1/27/21 and has been updated for more recent content.
Frequently Asked Questions
What are some PoseNet alternatives for implementing pose estimation in mobile apps for fitness?
You can also use OpenPose, which detects even fingers and face, and MobilePose, or DeepLabCut — if you’re tracking with animals.
What datasets are available for human pose estimation?
MPII and COCO for 2D pose detection; HumanEva, Human3.6M and SURREAL for 3D pose recognition.
If I go with the RealSense cam from Intel, can I still choose PoseNet over Intel's skeleton tracking SDK?
Yes, you’re free to choose a pose estimation model that works best for your product.